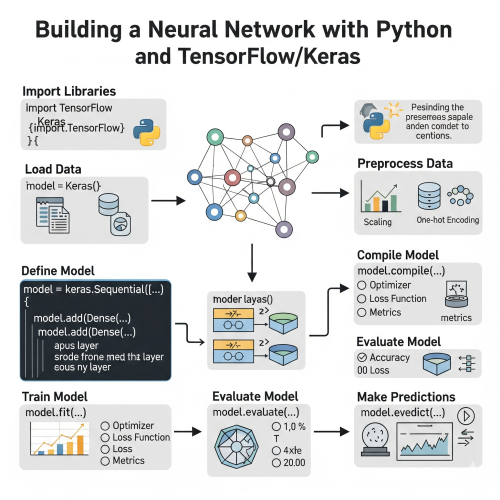




So you've built this amazing machine learning model that can predict customer behavior, classify images, or maybe even generate text. Great! But now comes the real challenge - how do you actually get this thing into production where real users can interact with it? Trust me, I've been there. You spend weeks perfecting your model only to realize that serving it to the world is a whole different beast.
Today, I want to walk you through one of the most reliable approaches I've found for deploying ML models: using FastAPI combined with Docker. This combo has saved me countless headaches, and I'm pretty sure it'll do the same for you.
Why FastAPI + Docker? Let Me Break It Down
Before we dive into the code, let's talk about why this particular stack makes sense. FastAPI isn't just another web framework - it's specifically designed with APIs in mind. It gives you automatic documentation (seriously, it's like magic), built-in data validation, and it's fast. Really fast. Plus, the async support means your API won't choke when multiple users hit it simultaneously.
Docker, on the other hand, solves the "it works on my machine" problem that haunts every developer. Your model might work perfectly on your laptop with Python 3.9, but what happens when your production server runs Python 3.8? Docker containers ensure consistency across environments.
Setting Up Your FastAPI Application
Let's start with a simple example. Say we have a trained scikit-learn model that predicts house prices. Here's how we'd wrap it in a FastAPI application:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import joblib
import numpy as np
import pandas as pd
from typing import List
# Load your trained model
model = joblib.load("house_price_model.pkl")
app = FastAPI(title="House Price Prediction API", version="1.0.0")
class HouseFeatures(BaseModel):
bedrooms: int
bathrooms: float
sqft_living: int
sqft_lot: int
floors: float
waterfront: int
view: int
condition: int
grade: int
yr_built: int
class PredictionResponse(BaseModel):
predicted_price: float
confidence: str
@app.get("/")
async def root():
return {"message": "House Price Prediction API is running!"}
@app.post("/predict", response_model=PredictionResponse)
async def predict_price(features: HouseFeatures):
try:
# Convert input to the format expected by your model
input_data = np.array([[
features.bedrooms,
features.bathrooms,
features.sqft_living,
features.sqft_lot,
features.floors,
features.waterfront,
features.view,
features.condition,
features.grade,
features.yr_built
]])
# Make prediction
prediction = model.predict(input_data)[0]
# Add some basic confidence logic
confidence = "high" if prediction > 300000 else "medium"
return PredictionResponse(
predicted_price=float(prediction),
confidence=confidence
)
except Exception as e:
raise HTTPException(status_code=400, detail=f"Prediction failed: {str(e)}")
@app.get("/health")
async def health_check():
return {"status": "healthy", "model_loaded": model is not None}
What I love about this setup is how clean it is. The Pydantic models handle all the input validation for us - if someone sends malformed data, FastAPI automatically returns a helpful error message. The health check endpoint is something you'll thank yourself for later when you're debugging deployment issues.
Creating Your Docker Setup
Now let's containerize this application. Here's a Dockerfile that I've refined through many late-night debugging sessions:
# Use Python 3.9 slim image as base
FROM python:3.9-slim
# Set working directory
WORKDIR /app
# Install system dependencies
RUN apt-get update && apt-get install -y \
gcc \
g++ \
&& rm -rf /var/lib/apt/lists/*
# Copy requirements first for better caching
COPY requirements.txt .
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application code
COPY . .
# Create non-root user for security
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
# Expose port
EXPOSE 8000
# Command to run the application
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
And here's the requirements.txt file you'll need:
fastapi==0.104.1
uvicorn[standard]==0.24.0
pydantic==2.5.0
scikit-learn==1.3.2
joblib==1.3.2
numpy==1.24.3
pandas==2.0.3
Handling Different Model Types
Now, not every model is a simple scikit-learn pickle file. Let me show you how to handle different scenarios. For deep learning models, you might be working with TensorFlow or PyTorch:
- For TensorFlow models, you can use SavedModel format or load from HDF5 files
- PyTorch models typically use .pth or .pt files with torch.load()
- Hugging Face transformers have their own loading mechanisms
- Custom models might need special preprocessing pipelines
Here's an example of how you might handle a TensorFlow model:
import tensorflow as tf
from fastapi import FastAPI, UploadFile, File
from PIL import Image
import numpy as np
import io
app = FastAPI()
# Load TensorFlow model
model = tf.keras.models.load_model("my_image_classifier.h5")
@app.post("/classify_image")
async def classify_image(file: UploadFile = File(...)):
# Read image
image_data = await file.read()
image = Image.open(io.BytesIO(image_data))
# Preprocess image
image = image.resize((224, 224))
image_array = np.array(image) / 255.0
image_array = np.expand_dims(image_array, axis=0)
# Make prediction
predictions = model.predict(image_array)
return {"predictions": predictions.tolist()}
Pro tip: Always include proper error handling and input validation. Your future self will thank you when you're troubleshooting why your API returns cryptic 500 errors at 2 AM.
Hard-learned experience
Optimizing for Production
Alright, so you've got your basic setup working, but there are a few more things you should consider before calling it production-ready. Performance optimization is crucial when you're dealing with ML models, especially if they're computationally intensive.
First, let's talk about model loading. Loading large models can take significant time, and you don't want to do this on every request. Here's a pattern I use for lazy loading:
from functools import lru_cache
import joblib
@lru_cache(maxsize=1)
def load_model():
"""Load model once and cache it"""
return joblib.load("large_model.pkl")
@app.post("/predict")
async def predict(data: InputData):
model = load_model() # This will only load once
prediction = model.predict(data.to_array())
return {"prediction": prediction.tolist()}
Docker Compose for Complete Setup
When you're ready to deploy, you might want additional services like Redis for caching or a database for logging predictions. Docker Compose makes this easy:
version: '3.8'
services:
ml-api:
build: .
ports:
- "8000:8000"
environment:
- REDIS_URL=redis://redis:6379
depends_on:
- redis
volumes:
- ./models:/app/models
restart: unless-stopped
redis:
image: redis:7-alpine
ports:
- "6379:6379"
restart: unless-stopped
nginx:
image: nginx:alpine
ports:
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
depends_on:
- ml-api
restart: unless-stopped
Monitoring and Logging
You can't manage what you don't measure. Adding proper logging and monitoring to your ML API is essential. Here's how I typically set up basic logging:
import logging
from fastapi import FastAPI, Request
import time
import json
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = FastAPI()
@app.middleware("http")
async def log_requests(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
process_time = time.time() - start_time
log_data = {
"method": request.method,
"url": str(request.url),
"status_code": response.status_code,
"process_time": process_time
}
logger.info(json.dumps(log_data))
return response
Security Considerations
Security might not be the most exciting part of ML deployment, but it's absolutely critical. Here are some basics you should implement:
- Always run your container as a non-root user (we did this in our Dockerfile)
- Implement rate limiting to prevent abuse of your API
- Use HTTPS in production - never serve ML models over plain HTTP
- Consider API key authentication for production deployments
- Validate and sanitize all inputs, even if you trust the source
Here's a simple rate limiting example using slowapi:
from slowapi import Limiter, _rate_limit_exceeded_handler
from slowapi.util import get_remote_address
from slowapi.errors import RateLimitExceeded
limiter = Limiter(key_func=get_remote_address)
app.state.limiter = limiter
app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
@app.post("/predict")
@limiter.limit("10/minute")
async def predict(request: Request, data: InputData):
# Your prediction logic here
pass
Testing Your Deployment
Before you push to production, you need to test everything thoroughly. I can't stress this enough - ML models in production can behave differently than in your development environment. Here's a simple test script I use:
import requests
import json
import time
# Test data
test_data = {
"bedrooms": 3,
"bathrooms": 2.0,
"sqft_living": 1800,
"sqft_lot": 7200,
"floors": 1.0,
"waterfront": 0,
"view": 0,
"condition": 3,
"grade": 7,
"yr_built": 1995
}
# Test the API
def test_api():
url = "http://localhost:8000/predict"
start_time = time.time()
response = requests.post(url, json=test_data)
end_time = time.time()
print(f"Status Code: {response.status_code}")
print(f"Response Time: {end_time - start_time:.2f} seconds")
print(f"Response: {response.json()}")
if __name__ == "__main__":
test_api()
Common Pitfalls and How to Avoid Them
Let me share some mistakes I've made (so you don't have to). The first big one is memory management. ML models can be memory-hungry, and if you're not careful, your container will get killed by the OOM killer. Always set appropriate memory limits in your Docker setup and monitor your usage.
Another common issue is dependency conflicts. Your model might have been trained with one version of scikit-learn, but your production environment has a different version. This can lead to subtle bugs that are incredibly hard to track down. Pin your dependencies and test thoroughly.
Model drift is another beast entirely. Your model performs great on training data, but real-world data changes over time. Implement monitoring to track prediction quality and be prepared to retrain your models regularly.
The best ML deployment is one that can gracefully handle the unexpected. Build in redundancy, monitoring, and fallback mechanisms from day one.
Murphy's Law in action
Scaling Considerations
Once your API is running and users start hitting it, you'll need to think about scaling. The beauty of the Docker approach is that you can easily spin up multiple containers behind a load balancer. Here are some strategies I've used:
Horizontal scaling works well for stateless ML APIs. You can run multiple instances of your container and distribute requests among them. Tools like Kubernetes make this relatively straightforward, though there's definitely a learning curve.
For models that are too large to fit in memory on a single machine, you might need to look into model serving frameworks like TensorFlow Serving, TorchServe, or MLflow. These tools are specifically designed for production ML workloads and can handle things like model versioning and A/B testing.
Caching is your friend when it comes to ML APIs. If you're making the same predictions repeatedly, store them in Redis or another fast cache. This can dramatically improve response times and reduce computational load.
Deployment Options
So where do you actually deploy this thing? You've got plenty of options, each with their own trade-offs. Cloud platforms like AWS, GCP, and Azure all have container services that make deployment relatively painless. AWS ECS, Google Cloud Run, and Azure Container Instances are all solid choices.
If you want something simpler, platforms like Heroku or Railway can deploy your Docker containers with minimal configuration. They're great for getting started, though they might not give you the control you need for more complex deployments.
For high-traffic applications, Kubernetes is probably your best bet. It's complex, but it gives you incredible control over scaling, monitoring, and resource management. There are managed Kubernetes services on all major cloud platforms that can help reduce the operational overhead.
The key is to start simple and scale up as needed. Don't over-engineer your first deployment - get something working in production first, then optimize.
Wrapping Up
Deploying ML models doesn't have to be a nightmare. FastAPI gives you a robust, fast web framework that's perfect for ML APIs, while Docker ensures your deployment is consistent and reproducible. The combination has served me well across dozens of projects, from simple classification APIs to complex multi-model ensembles.
Remember, the goal isn't to build the perfect deployment from day one. Start with something simple that works, then iterate and improve. Monitor everything, handle errors gracefully, and always test your deployments thoroughly before pushing to production.
The ML model is just the beginning - getting it reliably serving predictions to real users is where the real value lies. With FastAPI and Docker in your toolkit, you're well-equipped to make that happen.






0 Comment